|
2023年6月15日,英特尔公布将对自己的移动平台酷睿处置器停止「品牌升级」,移动平台中非性能处置器(即非HX处置器)被命名为intel Core X(3/5/7)大概intel Core Ultra X(3/5/7),其中采用Raptor Lake架构的小改款名字不带Ultrta,而采用新一代Meteor Lake结构的新平台名字中带有Ultra。由于Core X和Core Ultra X今朝都还是第一代产物,是以这个产物线的中文名别离叫「英特尔酷睿第1代处置器」和「英特尔酷睿Ultrta第1代处置器」。
虽然英特尔暗示移动平台高性能处置器和桌面端处置器临时原本的品牌名,但很多玩家都以为英特尔会趁着桌面14代酷睿的时候点,一并更换桌面处置器的品牌名,从而实现品牌称号的同一。
图片来历:英特尔
固然了,这些也都能够只是英特尔的开释的障眼法,其方针是让大师把留意力放到英特尔产物的名字,而不是14代酷睿采用的Raptor Lake上。但不管英特尔怎样想,留给他们的时候已经不多了。一方面,依照英特尔的更新节奏,新一代桌面酷睿最快10月份就要跟我们碰面了。另一方面,按照网上关于14代酷睿的爆料,14代酷睿的设置并没有大师料想中那末好。
13代酷睿的能力增强版?
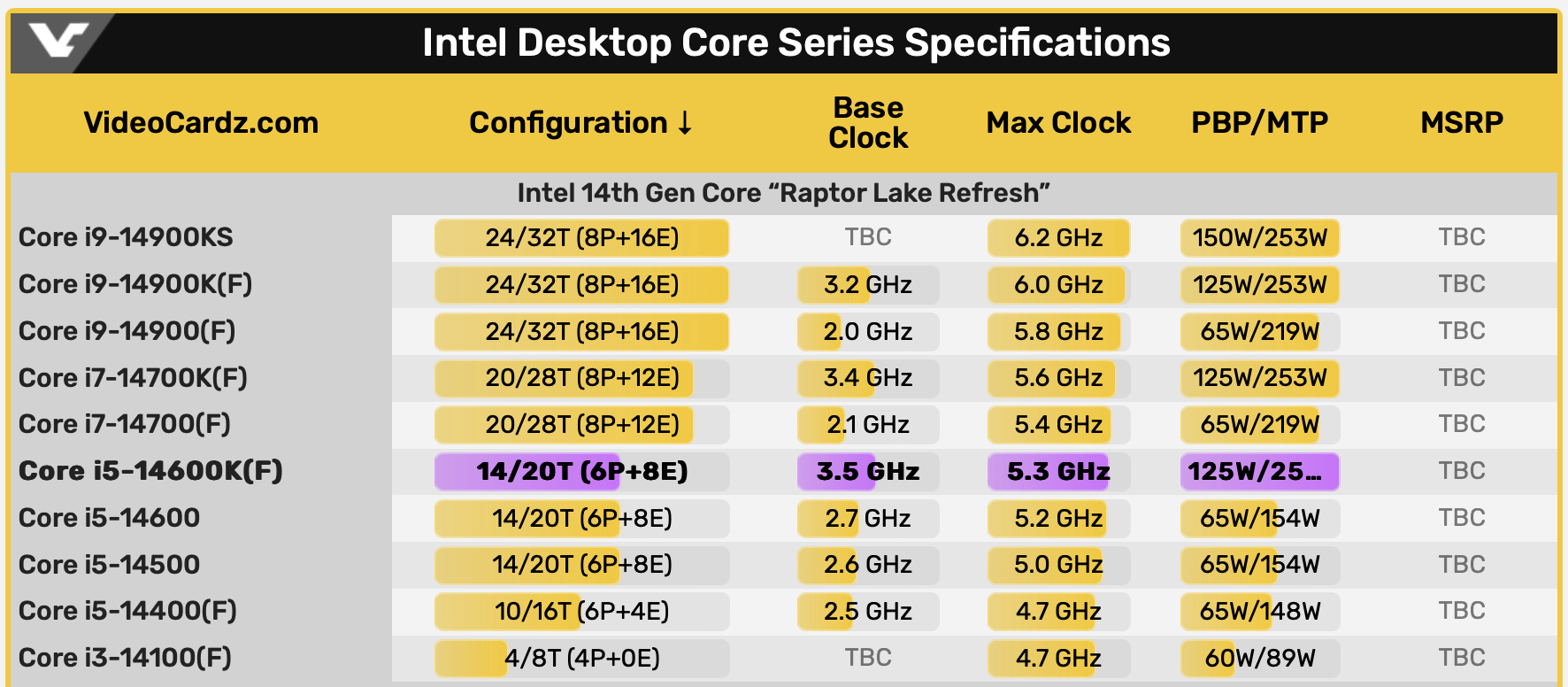
在最起头的「爆料」中,14600系列处置器将从原本的6P4E设置升级为和13700不异的8P8E设置,最大睿频也将提升到5.2GHz。假如该消息失实,这意味着新14代i5可以在不需要算法优化、仅凭仗硬件设置的情况下追平13代i7处置器,同时还具有更好的功耗控制。但在前段时候爆出的CPU-Z截图中,被我们寄与厚望的14600K照旧采用了6E8P、14焦点设置,L3缓存也照旧逗留在24MB而不是最初爆料的30MB,仅最大睿频提升到5.3GHz。
图片来历:VideoCardZ
值得留意的是,截图中配合14600K测试的主板南桥并不是传闻中「Z890」而是「Z790」,且插槽也是当前12代、13代酷睿所利用的LGA 1700插口。接口不换、设置不换、制程工艺也都还是10nm、仅频次稍微上调,说真话英特尔这样很难让人相信全新的14代桌面酷睿本质上不是13代、甚至是12代酷睿的「能力增强版」。
除了14600K的参数外,VideocardZ也公布了所谓的LGA1700接口生态图:14代照旧分为i9/i7/i5/i3四个品级,其中i9供给900/900K/900KS三种型号,均采用8P16E的焦点设置,最大睿频依次为5.8GHz/6.0GHz/6.2GHz,和13代的版底细比各提升了200MHz。
假如终极公布的14代处置器表示真如VideocardZ的汇总表所猜测的那样,那最少证实了两件事:一是英特尔在12代酷睿中提出的「巨细核」概念确切很是超前,二是英特尔未来极能够又得在约请函里放一管高露洁牙膏了。
英特尔的底气在那里?
从好的方面看,英特尔即使真的在14代酷睿上挤牙膏,也没有像Apple那样在新一代处置器的关键性能上动刀、让新产物的读写性能还不如上一代的老产物,甚至在最大睿频上还有些许提升到,为消耗者带来了200MHz的官方超频。
再说了,借助12代、13代两代酷睿,英特尔已经证实了「一般用户并不在意硬件上实打实地升级,反而更在意那些笼统化的虚拟目标」,比如运算性能提升、基于新编码获得的编解码效力提升、以及更重要的AI性能。要晓得英特尔公布的新一代至强W处置器采用的可是实打实的全P核设置,换句话说,英特尔很是清楚对性能有要求的工作站用户究竟需要怎样的处置器。
图片来历:英特尔
但英特尔照旧愿意在酷睿处置器中采用「巨细核」的计划,这实在也从市场反应的角度证实了一般用户并不需要「性能超群」的处置器,他们需要的仅仅是「优异的性能表示」。至于这个优异的性能表示来自更高本钱的硬件堆砌?还是来自更智能的AI算法,比如英特尔ITD(Intel Thread Director)。
换句话说,是AI技术给了英特尔挤牙膏的底气。
不管是英特尔还是英伟达,在这几年都起头夸大操纵AI技术进步硬件的性能表示。在最初,这类做法被以为是品牌的硬件盈利已经到头,希望用本钱更低的AI技术冲破硬件的制程限制,用更低的本钱实现性能的奔腾。
5月底,英伟达公布了最新一季财报,在游戏和专业可视化支出继续大跌的布景下,数据中心支出到达创记载的42.8亿美圆。电话会议上,黄仁勋诠释说:
计较机行业正在同时履历两种改变——加速计较和天生式AI。随着各个公司竞相为天生式AI摆设加速计较,代价1万亿美圆的全球数据中心根本设备将从通用计较转向加速计较。
这类改变不但发生在数据中心,还发生在全天下的PC和智妙手机上。早前的一场媒体味上,英特尔就在一台轻薄笔记本上展现了经过当地运转Stable Diffusion天生图片的进程。
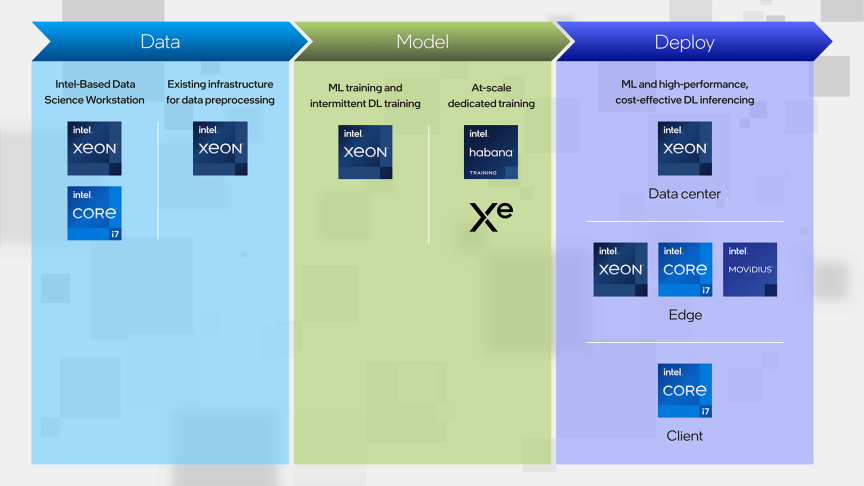
英特尔客户端计较奇迹部终端生态合作亚洲区总监高源流露,新一代Meteor Lake处置器将会分解CPU、GPU以及专门面向AI加速的自力计较单元VPU。不但如此,CPU、GPU以及VPU将配合介入AI加速计较的进程,使得在轻薄型PC成为能够。
图片来历:英特尔
换句话说,不管笔记本还是台式机,未来都一定会和AI技术发生交集。唯一的不肯定性是在AI时代,小我电脑将以怎样的身份加入到AI系统傍边。是完整的算力中心?可以毗连云端算力的边沿节点?还是退化成一个只用来与AI发生交互的终端载体呢?
当地化AI打破摩尔定律?
出于对小我数据的考量,小雷实在更希望将关键的AI数据以离线方式保存在当地。这一方面是为了保证小我数据不会毗连到互联网,另一方面也是斟酌到收集毗连的不肯定性。要晓得现在的5G收集就连几个智能灯泡都搞离线,我不敢设想在云端「拉闸」的情况下,基于AI运转的计较机系统能否还有运作的能够。
再说了,同时AI作为一种根本设备,未来应当被一切人利用,利用处景也将极为普遍,包括轻负载和重负载场景,也包括对延时比力敏感的场景。而从数据传输到云端处置,再回传成果,其中必定会有收集延时的影响,一些AI使命能够不需要太高的加速性能,反而要求更低的延时。
图片来历:英特尔
一言以蔽之,来自云真个算力没法覆盖更多的AI利用处景,也满足不了更多人的AI利用需求,AI不成能只「活」在云端。这一点在英特尔给出的「AI生态图」中也有所展现:「Deployt」(摆设)分类下,酷睿i7同时出现在了Edge(边沿计较)和Client(客户端)两栏中。
在前未几竣事的Computex上,高通资深副总裁暨运算及游戏部分总司理Kedar Kondap说,斟酌到延时、效力和适用性等题目,部分计较于手机、平板或电脑中、部分则在云端运转,「未来的AI计较是夹杂的。」
可以必定的是,为AI供给算力支持一定会是小我电脑接下来的成长重点,而基于AI二次开辟出的全新利用处景也会从场景侧反过来填补硬件侧的技术短板,甚至让芯片成长跳出「摩尔定律」的限制,用算法为硬件带来更多的能够性。
| 
![曹滟莉2023 - 粤语经典 古筝专辑 [WAV+CUE]](data/attachment/block/67/679ed37012c0c0cddbe2d7fc34f4b757.jpg)
![曼里《爱有天意》2023头版限量编号24K金碟[WAV+CUE]](data/attachment/block/78/788b19689a9f3e8c74c236b01c2f16bb.jpg)
![杨乐婷《天长地久 (HQⅡCD头版限量编号)》[正版CD低速原抓WAV+CUE]](data/attachment/block/60/60524fa971368b77a2ec6356df61996a.jpg)